For my last post comparing serverless offerings on a number of angles, I was struck again by the complexity of cloud pricing, which I alluded to at the end of the article.
Of course there is the great convenience of the cloud and all that it does for us, but there is also the substantial complexity of all that is offered, and the way it is priced.
This is a good article to read if you are thinking about this stuff:
My biggest beef is that I have to do actual research to understand the skus and how they work, in order to do price comparison. The APIs themselves do not (in any way shape or form) describe the service offering.
So: I Google, I read, and I figure it out. At least Google now offers this:
Which is a very helpful research tool, for their own cloud offering.
The other providers should do something like it. And they should give you programmatic access.
These systems all lack some definitive way to identify the pertinent skus. As a result, I'm hardcoding things (for now) and thinking about how this could be done better in the future.
Even if the values are stored in a database or configuration, I will need to add new ones, stay up to date, etc.
For real dynamic pricing, it would be better if there was an API that could be called to retrive relevant skus for any given service. Something like this, "Dear AWS, please give me all skus relevant to pricing of Lambda functions in East US 1". This would SHOULD be a simple API to use, and they have all the information to build it but they don't think about things that way.
The Google tool sort of does this, but you get back much more information and you still have to sort through skus to figure it out.
Anyway, billing APIs are not sexy nor are they money makers for these guys, but meaningful automation that will matter to the CFO will depend on services like this.
If I have to maintain a list of skus, then my pricing engine will always be a bit brittle. Fine for research, not great for prod.
As part of my Pricekite(also on GitHub) development work, I have been digging deep into the pricing model and use of serverless functions, this post will summarize statically, what you can find dynamically on Pricekite - from a compute cost perspective.
We will also look at development approaches and options for the serverless functions options from the three big players:
AWS Lambda
Google Cloud Functions
Azure Functions
Pricing
Winner: AWS
AWS and Azure
AWS and Azure price in more or less exactly the same way. They price based on what is called a Gigabyte-second. This unit of measure expresses the cost of a function using a gigabyte of memory for 1 second.
If you do not have a full gigabyte provisioned, then the amount charged for an actual clock second is a fraction of that amount. Or if you have more than a gigabyte, it is a multiple of the rate.
Both Amazon and Azure also charge for invocations. For the examples below I am assuming that the functions have allocated 512 MB of memory, which means that any function will be charged for a half GB-second for every clock second it runs.
Google
Google prices based on a memory allocation for time and for processor time, instead of rolling those into a single measure. This provides for more granularity in their pricing and probably lower pricing for workloads using less memory.
Since the CPU size you get is tied to the amount of memory, and we are using 512 MB for the memory, the CPU we are using has a clock speed of 800 MHz.
Pricing Scenarios
In order to try and make this somewhat sane we are using the following assumptions:
Function has a run time of 200 ms, regardless of platform.
Function is assigned 512 MB of memory.
On Google Cloud this implies an associated clock speed of 800 MHz.
The month we are discussing has 30 days, and therefore 2,592,000 seconds.
Each function (running 200 ms) will be invoked 12,960,000 times in the 30 day period.
We will look at the following 2 scenarios and compare prices:
A system that consists of 2 functions that run non-stop over a monthly period.
Price for 1 function running non-stop for a month, minus all discounts.
The first scenario is meant to show a reasonable amount of use that is still impacted by the discounts.
I understand that the exact scenario is unlikely, but it represents a pretty significant amount of invocations and CPU time. This same number of invocations and CPU time could be spread out over 5 or 10 or 100 functions, and the computations would be the same (assuming each function ran at 200 ms per invocation).
The second scenario is important because as you scale up the discounts will come to mean less and less, this scenario gives the sense of a per unit price, that actually represents real work.
Scenario 1: 2 Functions
Because we are running 2 functions at 512 MB memory, the GB Seconds is equal to:
AWS' discounts still matter a lot at this point. The 2 million GB Seconds add up to a lot.
Google's higher per invocation charge hurts them. It costs you more, the quicker your functions run. Said differently: if you have long running functions (200 ms is not long running) you will spend less on those pricey invocation charges.
Google is, overall, more expensive. They charge for more types of things and they charge more for those things.
Scenario 2: 1 Function, No Discounts
This is not a real world scenario (since discounts would apply), but the more functions you run, the smaller % of the total the discount is going to be.
So, if we consider a single function at 512 MB running for a full month (2,592,000 seconds) as our unit. What is our per unit cost, as we scale up?
AWS
AWS Item
Rate Per Unit
Unit
Units Consumed
Units Charged
Cost
CPU/Memory
$0.0000166667
GB Seconds
1,296,000
1,296,000
$21.60
Invocations
$0.0000002
Invocation
12,960,000
12,960,000
$2.59
Total
--
--
--
--
$24.19
Azure
Azure Item
Rate Per Unit
Unit
Units Consumed
Units Charged
Cost
CPU/Memory
$0.000016
GB Seconds
1,296,000
1,296,000
$20.74
Invocations
$0.0000002
Invocation
12,960,000
12,960,000
$2.59
Total
--
--
--
--
$23.33
Google Cloud
GCP Item
Rate Per Unit
Unit
Units Consumed
Units Charged
Cost
CPU
$0.00001
GHz Seconds
2,073,600
2,073,600
$20.74
Memory
$0.0000025
GB Seconds
1,296,000
1,296,000
$3.24
Invocations
$0.0000004
Invocations
12,960,000
12.960,000
$5.18
Total
--
--
--
--
$29.16
Take aways from Scenario 2:
Azure's per unit price is lower, but not by much. Once you have 32 such functions (of traffic equivalent to that) and your bill is over $730, Azure's lower per unit makes up for Amazon's initial discounts. So, if you have that kind of traffic, Azure is more cost effective.
Google's per unit price is higher. Long-running functions would cost less, but probably not by enough to make a difference. They're still the more expensive option.
It is also interesting to note that Azure's published rate on their website of .000016, is less than what comes back from their pricing API for any region. So, if you look at pricekite.io, the numbers are different.
I am assuming for the purposes of this analysis that their published numbers are correct.
Local Development
Winner: Microsoft
But of course, compute cost alone is not everything. For many implementations, labor costs and support costs will also factor in as a significant cost of the solution. So, next we will look at the tools that go in to working on these serverless functions.
By local development, I mean what does it take to work on these serverless functions, if you are going to work on your local machine? This is in contrast to working in the web-based editor that each company provides. I will cover the web-based editors below.
Microsoft
Developing locally with Microsoft means using Visual Studio. There may be other ways to do it, but if you are already a .Net developer then you have Visual Studio. If you do, then creating functions, running, and debugging them is very simple and easy to do. It even lets you emulate azure storage locally OR connect to your azure subscription and use real Azure resources. This is amazingly simple and comes with all that you need to do local development.
It is even easy to set breakpoints in the code (just as you'd expect from any other C# development in Visual Studio). There are code templates (in VS 2019) you just select, walk through the wizard, and you are up and coding.
Also, Microsoft is clearly the cloud of choice if you are already a .Net shop and like writing C# code.
A few screen shots:
Code Templates and Built-in Azure Integration make Visual Studio easy to work with.
Google
Google does not have a tool anything like Visual Studio. So if you are going to work on Google Cloud Function code locally, you will be using your favorite editor: Web Storm, Atom, etc.
The nice thing about working locally is that Google Makes this very easy through some local tools that you can install on your computer via NPM, and which can be started off with a couple simple command lines using their Functions Framework.
All in all it is very easy and works out of the box if you are used to node.js and NPM, which you should be if you are going to write Google Cloud Functions.
AWS
The truth is, I did not get it to work.
In order to do local development you need several things installed which I did not have AWS-CLI and Docker, being the two I can remember off the top of my head. I did get them both installed (eventually) and running.
I was able to run the template creation of a basic "Hello World" but when I ran it, it failed. I believe the problem was with Docker. The only online help I found with my problem was to ensure that I was running Linux and not Windows Docker containers, but I was already doing that.
I believe that it does work. And if you are more deeply enmeshed in the AWS world, you can probably get this working, without any problem. I didn't. Compared to the other two it was hard.
For the record, I had to install VS 2019 on a machine which had never had any previous version of VS on it. It took a while, as VS installs do, but everything worked exactly right, out of the box, the first time.
I spent probably 1 - 2 hours messing with local Amazon development before I gave up.
Cloud-Based Development
Winner: Amazon Lambda
Now we will talk about doing development in the web interface. This is where Amazon really shines. They bought a company called Cloud9 (web-based IDE) a few years ago and it shows.
You can still use Cloud9 as a separate, web-based development product for other development, some features and UI concepts have been brought in to the Lambda funciton editor.
Amazon
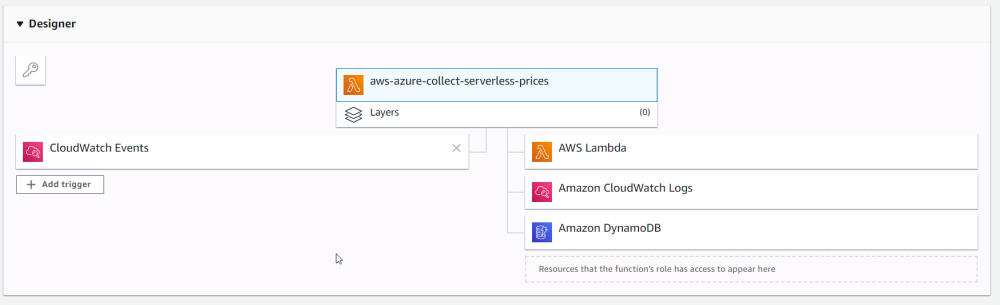
There is a lot to like about doing Lambda function development inside of the AWS Console. My maybe-favorite thing, is not really a development thing at all. It is this:
The Designer
This Designer thingy shows you all of the Lambda function's permissions in a neat user interface. I don't know if Amazon thought of this or it came from Cloud9, but it is genius and very helpful and every system in the world should copy it. Azure especially needs this.
The development piece is straightforward, has good syntax highlighting and catches pretty much all your syntax errors for you.
There is built in testing, log tracing, performance configuration, permissions, performance monitoring, and network info. And it is all on one page, intuitively laid out, helpful, and easy to use. This is where AWS maturity comes into full view.
There are times in life where you have to sit back and appreciate what I call a million dollar page or screen This right here is a million dollar web page, and it is a million dollars well invested.
The main drawback is that you cannot simply add node.js packages to the web-based editor, you can only do that locally. But I honestly found that the included packages work for all my use cases. The built-in packages include the AWS JavaScript SDK (I evaluated node.js, not python), which has A LOT of functionality.
Microsoft
Microsoft probably gets second place, as there are some things that they do really well. You can easily add additional dlls for references to have your code do more. The code editor (for C#) is on par with AWS in terms of syntax checking and highlighting. And the built in log-tracing was even better (when it worked).
Only sometimes it didn't work. Sometimes it just stopped working for reasons that I never completely understood, causing me to have to reload the page (annoying).
Google
Google has the least exciting looking interface. And it is not nearly as full featured as either MS or AWS. There is no onscreen logging, and the process of changing code required a redeploy (10 - 15 seconds) to test it. You also have to pop in and out of editing mode, which takes time also. The best thing about Google is that they make it very comfortable for node.js developers to work there. You can edit the file with the js code (usually index.js) and you can edit the package.json file to add includes, all very easy if you are familiar with that ecosystem.
Google makes it very easy to deploy from their Cloud Source Repositories, which includes an easy integration to Git. So it is easy to deploy from an external source repository. It is all built into the UI and very clean. Honestly, I don't know if security people would love that, but it is a handy feature.
Who Should You Pick?
Well, the answer is, "It depends."
AWS has the edge in both price and online code editing, which I think makes them the strongest player.
If you are a .Net shop or have other reasons to work locally, Visual Studio's local development capabilities are very strong.
There are a lot of other real world scenarios to consider and you should consider these things as well when you are evaluating these tools:
What else does your application do?
What type of other services do you need?
What deployment model do you want?
What are your QA Automation goals?
Are you a start up?
What size of payload are you sending in to your functions?
All of those things are important, as is this question: "What are you already using?" If you have significant investment, you have to look at the cost of change, as well.
I think that you can look at this and be upset about just how complex some of these things are. But honestly, I think that from a capability stand point it is just amazing what the cloud has to offer and how powerful this stuff is. Also, if you think there isn't job security in understanding and making sense of these tools for your organization, I think you're missing the big picture.
This post is a follow up to my earlier posts on so called fragile or spaghetti code where I made a point about reading code - not the most fun part of anyone's day, but it generally makes code a lot less 'fragile' if you do it.
This idea is the equivalent of taking the time to read the instructions - you're a lot less likely to break something if you know how you're supposed to operate it.
This post is still about code fragility, but it is about code that actually is fragile, only it is fragile on purpose.
There are a number of reasons why this can happen, I will illustrate them from some recent work I've been doing, as well as some client projects. But first I am going to focus on what people mean by 'fragile', so it is clear what this means.
You may hear the phrase 'this code is fragile' and think that that means that it doesn't work, or that there are purposes to which it is not suited. As in, 'This vase is fragile so I probably shouldn't fill it with chunks of broken concrete.
But this is really not what 'fragile' code means. Usually it means:
This code is hard to work on and it is likely to break if I do something to change it.
This code may break in the future if the conditions in which it runs change.
This code may break if any of our integration partners alter their API.
This code does not fail gracefully.
This code is not commented well and that makes it hard for me to read and understand what it doing.
As it pertains to number 1, this is just the scenario from the other article where you aren't working hard enough to understand it. Said differently, you are really saying, "My understanding of this code is fragile."
I put 1 and 5 at opposite ends of this list for a reason. Because 5 should not be an obstacle to reading code. It is a better excuse, than 1 for your lack of progress, but it still an excuse. Poorly commented code simply means you have to spend more time reading, testing, debugging the code to understand it. No code is ever commented well enough in my opinion, so you can't let it stop you from working on it. Code can be readable or unreadable, it can be commented or not, but that should not stop you from understanding it if you know what you are doing and that is your job. You can get a different job, but chances are you will be in the same situation there.
5 is only worth noting separately, because you should plan for and avoid that situation. Try to avoid committing this sin if you can.
For both 2 and 3, a significant portion of what will happen in the future is unknowable, and so how much time you spend dealing with 2 and 3 should be carefully callibrated. You can know that a partner is going to publish an API update in 6 months if they tell you, but if you need to go live now you may simply have to deal with that change when they publish it or make it the new API available for testing.
Of course with failures and crashes (number 4) you should avoid these things and use defensive coding practices to avoid exposing your users to failures, even if they originate outside of your systems. A few examples:
A good NoScript section of your website.
A graceful handling handling of offline operation.
Handling nulls, empty strings, and other straightforward data situations.
Use exception handling properly to deal with unexpected situations
Etc, etc.
But be careful of swallowing problems within the system - you may protect users and also hide them from yourself, only to have them come back and bite you later on.
It's always surprising to me how many people present an utterly, blank empty page to the user if JavaScript is not enabled or working.
OK, so here we are. We need to do some development work. We have coding practices to deal with number 4 and 5. We're working on a new system, so hopefully number 1 is a non-issue. What, if anything should we do about 2 and 3?
My answer is: it depends.
Truthfully, you can't predict the future or what your integration partner will do to update their API until they publish a specification.
We were recently working through updating a Dialogflow implementation for v2, but we couldn't have changed anything or done anything until they published their v2 specs. It would have been guesswork.
As I've been working on my side project Pricekite.io, I am dealing with the billing APIs for AWS, Azure, and Google Cloud, each of which is in varying stages of development. I am faced with 2 challenges:
What are they going to do in the future to update these APIs?
What additional features am I going to want to add in the future?
My decision for both is to do nothing. If/when I decide to add a feature that requires me to improve code, I'll improve it. I had to add some data storage in order to have data on hand for 1 provider (cough Azure cough) because their billing API is not the most efficient thing in the world.
I had not intended to add data storage until phase 2, but my hand was forced by the 6 seconds it took to pull and process the data. So, I call the 6 second method every 30 minutes and store the values, which can then be pulled at any time. It introduces latency to the data, but that does not matter at this juncture at all. If it turns out to matter, I simply can crank up the frequency of the polling.
So, the code is fragile. But it works, and it was able to be written by 1 person quickly, and it will be very easy to read as, for the most part, you have absolute line of sight readability in the code.
As it relates to Pricekite.io, I've already moved on from this topic, and you won't see anymore blogs about it here. I'm currently deep into navigating the byzantine spaces of the cloud provider product catalogs to pull out serverless computing prices.
But, since I'm pretty sure there will never be a price spike, and since none of the dire predictions ever came true, it is worth considering why.
I have heard at least 3 reasons why we were going to run out of IP Addresses. Here are they are, and here are the reasons they haven't and won't happen:
People - with so many people in the world, and so many of them being online, we will run out of IP addresses because individuals (needing to carve out their digital homesteads) will use them up. Why did it not happen? The rise of online platforms allow people to join the online community without a traditional website and everything that comes with it. Facebook, Twitter, Pintrest, Medium, GitHub, Wix, etc. - you don't need a domain name or an IP address to be online with these services.
Businesses - Businesses, even more than people, need to be online so that people can find them and they can make money. Why did it not happen? Platforms are a part of this. Many business have Facebook pages or Google Sites and that is it, no IP address needed. Also, today you are able to create a web presence outside of a platform and you don't need an IP address to do it. Pricekite for instance has a unique domain and 2 subdomains, but because of cloud based development and neat DNS tricks it does not need an IP address.
IoT Devices - The idea here is that with billions and billions of connected devices we will run out of IP v4 addresses. Why did it not happen? IoT devices mostly don't use public IP addresses, which is as it should be. There's no reason for your refrigerator to be on the public internet (and therefore need a public IP address). It's dangerous enough having it on your home wifi with an internal address. Internal addresses are pretty much infinite, so the IoT devices aren't putting any pressure on the IP address space.
OK, that's it for my thoughts on IP Addresses. Look for more information on compute prices in the near future.
As part of my recent and ongoing interest in the price of IP Addresses, I'm putting together a site to get live reads on the prices from the 3 big cloud providers: Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP).
The site is now live with live data from GCP and is called pricekite.io. The prices for AWS and Azure are current, but do not refresh live from web services. The code is on GitHub.
A few observations and thoughts from the first part of this development:
Azure Permissions
I am currently stuck on the Azure implementation because of permissions. I know the least about Azure permissions, and they turn out to be quite complicated. I have followed the tutorials, but still it doesn't work. By contrast the GCP permissions are very simple to set up and work very cleanly, while allowing you to control access quite granularly.
This appears (on the surface) to be an arifact of legacy Active Directory. Microsoft needs to support a lot of older models that they have developed over the years for large clients, and can't simply abandon the ways of the past. In Google's case they have only the security and permission model developed for GCP with no legacy headaches to worry about. Such is the price of success.
GCP Pricing Details
Under the covers of GCP's pricing platform there are some interesting things to be aware of.
All of the items (and there are many of them) have the ability to be priced at a level of billionths of a dollar, or other currency.
Items are priced by:
Units - whole units of currency. Such as the USD or other currency.
Nanos - fractional units of currency equal to 1 billionth of the unit.
Take, for instance, our friend the old, reliable IP v4 Address. In this case, for unused addresses thay are priced at:
0 units and 15,000,000 nanos per hour
This means, that each unused address costs:
$0 + 15,000,000/1,000,000,000 per hour
Or in plain English: $.015/hour or $7.2/month.
Of course the fascinating thing here is the ability to control very fine grained level of pricing. Also, there is evidence that in the future they will be charging per second for some resources. Though I don't believe they do this today.
Next I am going to dive into the AWS implementation and leave my Azure frustrations behind. I'll post another update when I get the AWS pricing working.
 Jonathan Fries on .
Jonathan Fries on .